
Lecture 03: Data Types, Importing Data, and SQL Math
DATA 503: Fundamentals of Data Engineering
January 19, 2026
Today’s Agenda
Part 1: Hands-On Setup + Data Types
- Import our sample dataset
- Understanding PostgreSQL data types
- Choosing the right type for your data
Today’s Agenda (continued)
Part 2: Math Operators and Functions
- Arithmetic in SQL
- Rounding, absolute values, and precision
- Aggregate functions (SUM, AVG, COUNT)
Today’s Agenda (continued)
Part 3: Statistical Functions + Assignment Preview
- Finding medians and percentiles
- Date arithmetic and intervals
- Homework 2 walkthrough
Part 1: Getting Data Into PostgreSQL
Why Not Just INSERT Everything?
Imagine you have 65,000 survey responses…
This is:
- Slow (each INSERT is a separate transaction)
- Error-prone (one typo and you start over)
- Painful (your fingers will hate you)
Solution: Bulk import with \COPY
The Office: Our Sample Dataset
Today we will work with some Dunder Mifflin employee data again.
The Dataset
| employee_id | full_name | department | salary_usd |
|---|---|---|---|
| 1 | Michael Scott | Management | 75000.00 |
| 2 | Dwight Schrute | Sales | 62000.00 |
| 3 | Pam Beesly | Reception | 42000.00 |
| 4 | Jim Halpert | Sales | 61000.00 |
Expanded Dataset for Today
I have added a few more employees and columns so we can practice more SQL:
| employee_id | full_name | department | salary_usd | performance_rating | years_experience |
|---|---|---|---|---|---|
| 1 | Michael Scott | Management | 75000.00 | 3.2 | 15 |
| 2 | Dwight Schrute | Sales | 62000.00 | 4.8 | 12 |
| 3 | Pam Beesly | Reception | 42000.00 | 3.9 | 8 |
| 4 | Jim Halpert | Sales | 61000.00 | 4.1 | 10 |
| 5 | Angela Martin | Accounting | 52000.00 | 4.5 | 11 |
| 6 | Kevin Malone | Accounting | 48000.00 | 2.1 | 9 |
| 7 | Oscar Martinez | Accounting | 54000.00 | 4.7 | 13 |
| 8 | Stanley Hudson | Sales | 58000.00 | 3.0 | 20 |
Hands-On: Create the CSV File
Step 1: Create a file named employees_import.csv, I recommend in your Downloads directory for now.
Copy this exact content (hover over the data and click the copy button that appearsto the right):
employee_id,full_name,department,email,hire_date,salary_usd,is_manager,performance_rating,years_experience,commission_rate,last_login
1,Michael Scott,Management,michael.scott@dundermifflin.com,2005-03-24,75000.00,true,3.2,15,,2026-01-15 09:12:00
2,Dwight Schrute,Sales,dwight.schrute@dundermifflin.com,2006-04-12,62000.00,false,4.8,12,0.08,2026-01-16 08:01:00
3,Pam Beesly,Reception,pam.beesly@dundermifflin.com,2007-07-02,42000.00,false,3.9,8,,
4,Jim Halpert,Sales,jim.halpert@dundermifflin.com,2005-10-05,61000.00,false,4.1,10,0.07,2026-01-16 08:03:00
5,Angela Martin,Accounting,angela.martin@dundermifflin.com,2006-08-15,52000.00,false,4.5,11,,2026-01-15 07:45:00
6,Kevin Malone,Accounting,kevin.malone@dundermifflin.com,2007-02-28,48000.00,false,2.1,9,,2026-01-16 09:30:00
7,Oscar Martinez,Accounting,oscar.martinez@dundermifflin.com,2005-06-01,54000.00,false,4.7,13,,2026-01-16 08:15:00
8,Stanley Hudson,Sales,stanley.hudson@dundermifflin.com,2004-11-20,58000.00,false,3.0,20,0.05,2026-01-16 08:55:00Hands-On: Move the CSV to a Safe Location
Why a “safe” location?
PostgreSQL needs permission to read your file. Some folders are restricted.
macOS / Linux:
Windows (PowerShell):
Hands-On: Connect to PostgreSQL
Open your terminal and connect:
You should see a prompt like:
postgres=#Warning
- If your prompt spits out
command not found: psqlor something similar, psql is not in your PATH. Check out the resource on Canvas → Week 2 Lesson Plan → Adding PSQL to your PATH. - If you see
psql: could not connect to server: No such file or directoryor something similar, you are not connected to the database or there are credential issues. Trypsql -U postgres -h localhostinstead.
Hands-On: Create the Database
At the postgres=# prompt, run:
You should see:
You are now connected to database "office_db" as user "postgres".Note
The \c command connects you to the new database.
Hands-On: Create the Table
Now we need a table that matches our CSV columns exactly. Copy this exact content (hover over the data and click the copy button that appears to the right):
CREATE TABLE employees (
employee_id INTEGER PRIMARY KEY,
full_name TEXT NOT NULL,
department TEXT NOT NULL,
email TEXT,
hire_date DATE NOT NULL,
salary_usd NUMERIC(10,2) NOT NULL,
is_manager BOOLEAN NOT NULL,
performance_rating NUMERIC(2,1),
years_experience INTEGER,
commission_rate NUMERIC(3,2),
last_login TIMESTAMP
);Verify with \d employees to see the structure.
Understanding the CREATE TABLE Statement
Each column definition has:
- Name: What you call the column (e.g.,
salary_usd) - Data Type: What kind of data it holds (e.g.,
NUMERIC(10,2)) - Constraints: Rules the data must follow (e.g.,
NOT NULL)
Hands-On: Import the CSV
The moment of truth!
macOS / Linux:
Windows:
You should see: COPY 8
That means 8 rows were imported successfully!
Hands-On: Verify Your Data
Count the rows:
| count |
|---|
| 8 |
View all the data:
Take a moment to verify the data looks correct.
The Anatomy of \COPY
Let’s break this down:
| Part | Meaning |
|---|---|
\COPY |
Client-side copy command |
employees |
Target table name |
FROM '/tmp/...' |
Source file path |
FORMAT csv |
File is comma-separated |
HEADER true |
First row is column names |
\COPY vs COPY: What’s the Difference?
| Feature | \COPY |
COPY |
|---|---|---|
| Runs on | Your computer (client) | Database server |
| File location | Your filesystem | Server filesystem |
| Permissions | Your user permissions | postgres user permissions |
| Best for | Development, small files | Production, large files |
Rule of thumb: Use \COPY in this class. It is safer and easier.
Exercise: Check Your Import
Write queries to answer (work with a neighbor if your system is acting up):
- How many employees are in the Sales department?
- What is Michael Scott’s email?
- Which employee has the highest performance rating?
Take 3 minutes, then we will review.
Exercise Solutions
1. Sales department count:
| count |
|---|
| 3 |
2. Michael’s email:
| michael.scott@dundermifflin.com |
3. Highest performance rating:
| full_name | performance_rating |
|---|---|
| Dwight Schrute | 4.8 |
Data Types: Choosing Wisely
Why Data Types Matter
Consider this question: What is '10' + '5'?
- In some languages:
'105'(string concatenation) - In math:
15(addition)
Warning
Data types tell PostgreSQL how to interpret and operate on your data.
Wrong data type = wrong results, wasted storage, or errors.
PostgreSQL Data Type Categories
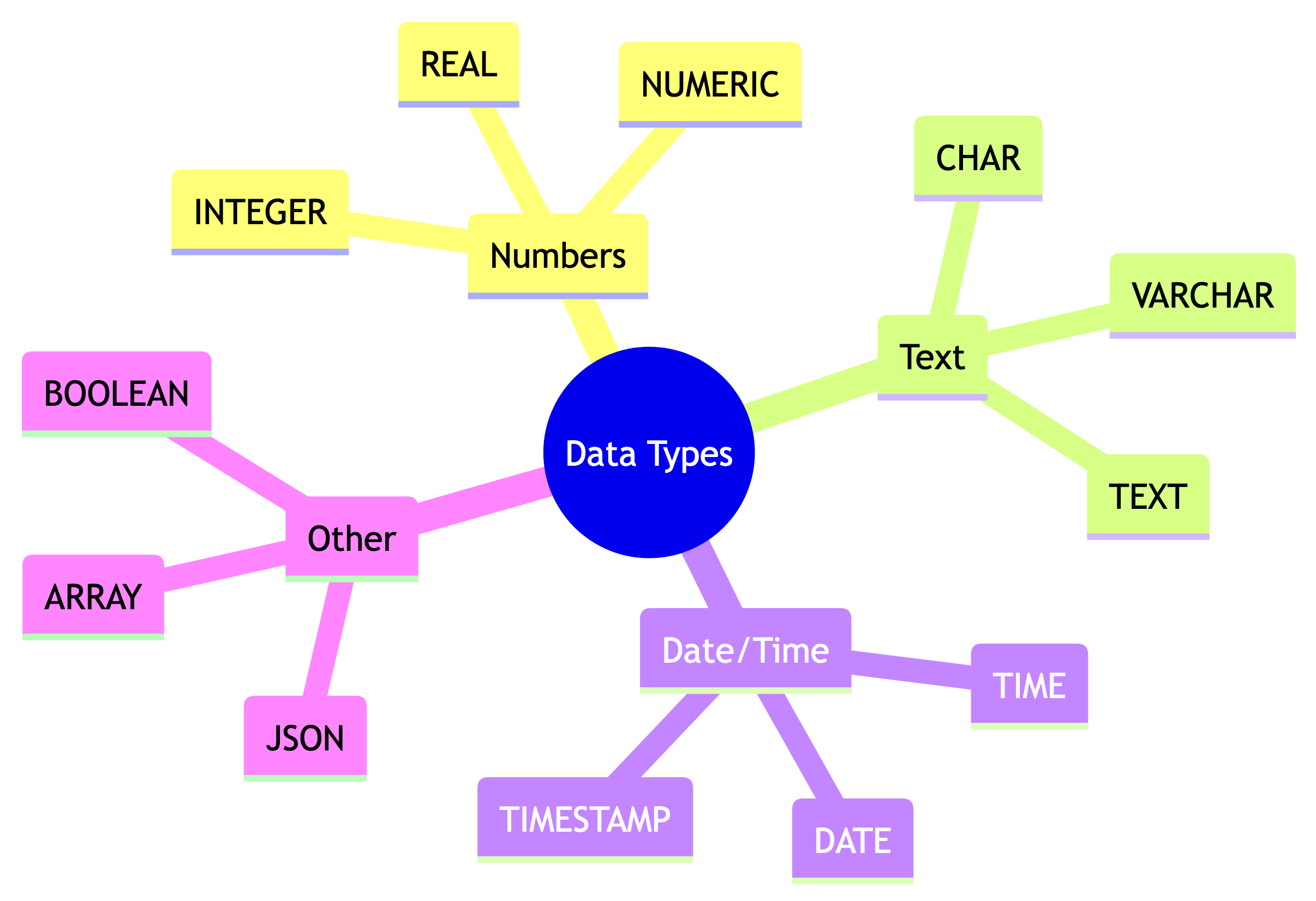
Numeric Types: The Big Three
| Type | Description | Example |
|---|---|---|
INTEGER |
Whole numbers | 42, -7, 1000000 |
NUMERIC(p,s) |
Exact decimals | 75000.00, 3.14159 |
REAL |
Approximate decimals | Scientific calculations |
When to use each:
INTEGER: Counts, IDs, quantitiesNUMERIC: Money, precise measurementsREAL: Scientific data where approximation is OK
NUMERIC(precision, scale) Explained
- Precision (10): Total digits allowed
- Scale (2): Digits after decimal point
| Value | Valid for NUMERIC(10,2)? |
|---|---|
| 75000.00 | Yes (7 digits total) |
| 123456789.99 | No (11 digits total) |
| 75000.001 | Rounded to 75000.00 |
Quick Check: Our Employee Table
Look at how we defined numeric columns:
Question: Why not use INTEGER for salary? 🤔
Because we want cents! $75,000.00 not $75000
Text Types: Three Flavors
| Type | Description | Use Case |
|---|---|---|
CHAR(n) |
Fixed length, padded | Codes like state abbreviations |
VARCHAR(n) |
Variable length, max n | Names, emails with limits |
TEXT |
Unlimited length | Long descriptions, notes |
Note
In practice: TEXT and VARCHAR are equally fast in PostgreSQL.
I generally use TEXT unless I have a specific length constraint.
Date and Time Types
| Type | Stores | Example |
|---|---|---|
DATE |
Year, month, day | '2026-01-15' |
TIME |
Hour, minute, second | '09:30:00' |
TIMESTAMP |
Both date and time | '2026-01-15 09:30:00' |
Boolean: True or False
The BOOLEAN type stores TRUE or FALSE.
PostgreSQL accepts multiple formats:
| True Values | False Values |
|---|---|
TRUE, 't', 'yes', '1' |
FALSE, 'f', 'no', '0' |
| full_name | is_manager |
|---|---|
| Michael Scott | t |
NULL: The Absence of Data
NULL means “unknown” or “not applicable.”
Look at our data for commissions:
| full_name | commission_rate | last_login |
|---|---|---|
| Michael Scott | NULL | 2026-01-15 09:12:00 |
| Pam Beesly | NULL | NULL |
| Angela Martin | NULL | 2026-01-15 07:45:00 |
Note
Pam has no commission (not in sales) AND no last_login (maybe she uses paper).
NULL Gotchas
NULL is not equal to anything, not even itself!
NULL Gotchas: Math with NULL
Math with NULL returns NULL
Note
We will learn to handle this with COALESCE and NULLIF later.
Exercise: Data Type Detective
Look at this data and choose the best PostgreSQL data type:
- Social Security Number:
'123-45-6789' - Product price:
$29.99 - Is item in stock:
yesorno - Number of items in warehouse:
1,547 - Customer review text:
'Great product! Would buy again...'
Take 2 minutes to decide, then we discuss.
Exercise: Data Type Answers
SSN:
CHAR(11)orVARCHAR(11)- It is text, not a number (leading zeros, dashes)Price:
NUMERIC(10,2)- Money needs exact precisionIn stock:
BOOLEAN- True/false valueWarehouse count:
INTEGER- Whole numbers onlyReview text:
TEXT- Variable length, potentially long
Next up: Math Operators and Functions
Stretch or grab coffee, then verify your import worked. ☕
Part 2: Math Operators and Functions
SQL as a Calculator
PostgreSQL can do math! Let’s start simple:
| ?column? |
|---|
| 4 |
No table needed. SQL evaluates the expression and returns the result.
Basic Math Operators
| Operator | Operation | Example | Result |
|---|---|---|---|
+ |
Addition | 5 + 3 |
8 |
- |
Subtraction | 10 - 4 |
6 |
* |
Multiplication | 6 * 7 |
42 |
/ |
Division | 15 / 4 |
3 |
% |
Modulo (remainder) | 15 % 4 |
3 |
Wait, what? 👀
15 / 4 = 3? d Yes! Integer division truncates. 🤯
Integer Division Trap
Note
Rule: If both operands are integers, result is integer.
Make at least one operand a decimal to get decimal results.
Hands-On: Math with Employee Data
Calculate annual bonus (10% of salary):
| full_name | salary_usd | annual_bonus |
|---|---|---|
| Michael Scott | 75000.00 | 7500.0000 |
| Dwight Schrute | 62000.00 | 6200.0000 |
| Pam Beesly | 42000.00 | 4200.0000 |
Calculating Percent Change
The formula: ((new - old) / old) * 100
Example: If salary goes from $50,000 to $55,000:
| pct_increase |
|---|
| 10.0 |
A 10% raise. (Nice!)
Hands-On: Salary Per Year of Experience
How much does each employee earn per year of experience?
| full_name | salary_usd | years_experience | salary_per_year |
|---|---|---|---|
| Pam Beesly | 42000.00 | 8 | 5250.00 |
| Jim Halpert | 61000.00 | 10 | 6100.00 |
| Dwight Schrute | 62000.00 | 12 | 5166.67 |
The ROUND() Function
ROUND(value, decimal_places) rounds to specified precision:
Note
Always ROUND money calculations for clean output!
The ABS() Function
ABS() returns the absolute value (distance from zero):
Using ABS()
Use case: Finding differences regardless of direction:
Hands-On: Distance from Average Salary
Let’s find how far each employee’s salary is from $55,000:
| full_name | salary_usd | difference | absolute_difference |
|---|---|---|---|
| Michael Scott | 75000.00 | 20000.00 | 20000.00 |
| Pam Beesly | 42000.00 | -13000.00 | 13000.00 |
| Dwight Schrute | 62000.00 | 7000.00 | 7000.00 |
Exponents and Roots
| Function | Description | Example | Result |
|---|---|---|---|
^ |
Exponentiation | 2 ^ 3 |
8 |
\|/ |
Square root | \|/ 16 |
4 |
\|\|/ |
Cube root | \|\|/ 27 |
3 |
SQRT() |
Square root (function) | SQRT(16) |
4 |
Exercise: Calculate Commission
Sales employees have a commission rate. Calculate their potential commission on a $10,000 sale:
Hint: Commission = sale_amount * commission_rate
Take 2 minutes.
Exercise Solution: Commission Calculation
| full_name | commission_rate | commission_on_10k |
|---|---|---|
| Dwight Schrute | 0.08 | 800.00 |
| Jim Halpert | 0.07 | 700.00 |
| Stanley Hudson | 0.05 | 500.00 |
Dwight’s higher rate reflects his #1 salesman status. Obviously.
Aggregate Functions
What Are Aggregate Functions?
Aggregate functions compute a single result from multiple rows.
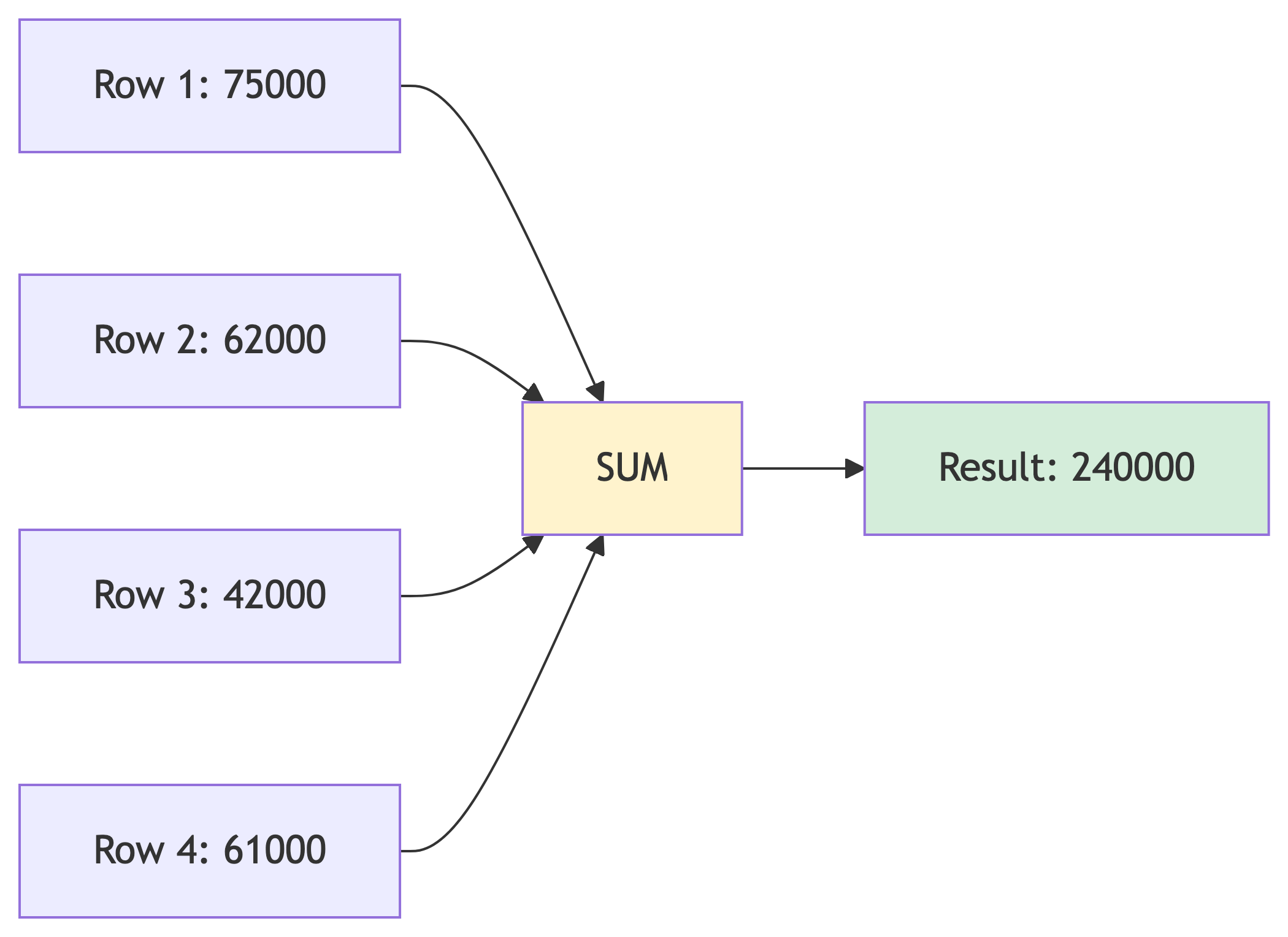
The Big Five Aggregates
| Function | Description | Example |
|---|---|---|
SUM() |
Total of all values | Total payroll |
AVG() |
Average (mean) | Average salary |
COUNT() |
Number of rows | How many employees |
MIN() |
Smallest value | Lowest salary |
MAX() |
Largest value | Highest salary |
SUM(): Total Values
What is our total payroll?
| total_payroll |
|---|
| 452000.00 |
We spend $452,000 on salaries. (Michael probably thinks he deserves half.)
AVG(): Calculate the Mean
What is the average salary?
| avg_salary |
|---|
| 56500.000000 |
That is a lot of decimal places. Let’s fix that:
| avg_salary |
|---|
| 56500.00 |
COUNT(): How Many?
Three ways to count:
| count(*) | count(commission) | count(distinct dept) |
|---|---|---|
| 8 | 3 | 4 |
Only 3 employees have commission rates!
MIN() and MAX(): The Extremes
Salary range:
| lowest_salary | highest_salary | salary_range |
|---|---|---|
| 42000.00 | 75000.00 | 33000.00 |
Pam makes the least, Michael makes the most. Shocking.
Combining Multiple Aggregates
You can calculate several aggregates in one query:
| num_employees | total_payroll | avg_salary | min_salary | max_salary |
|---|---|---|---|---|
| 8 | 452000.00 | 56500.00 | 42000.00 | 75000.00 |
GROUP BY: Aggregates by Category
What if we want average salary BY DEPARTMENT?
| department | num_employees | avg_salary |
|---|---|---|
| Management | 1 | 75000.00 |
| Sales | 3 | 60333.33 |
| Accounting | 3 | 51333.33 |
| Reception | 1 | 42000.00 |
How GROUP BY Works
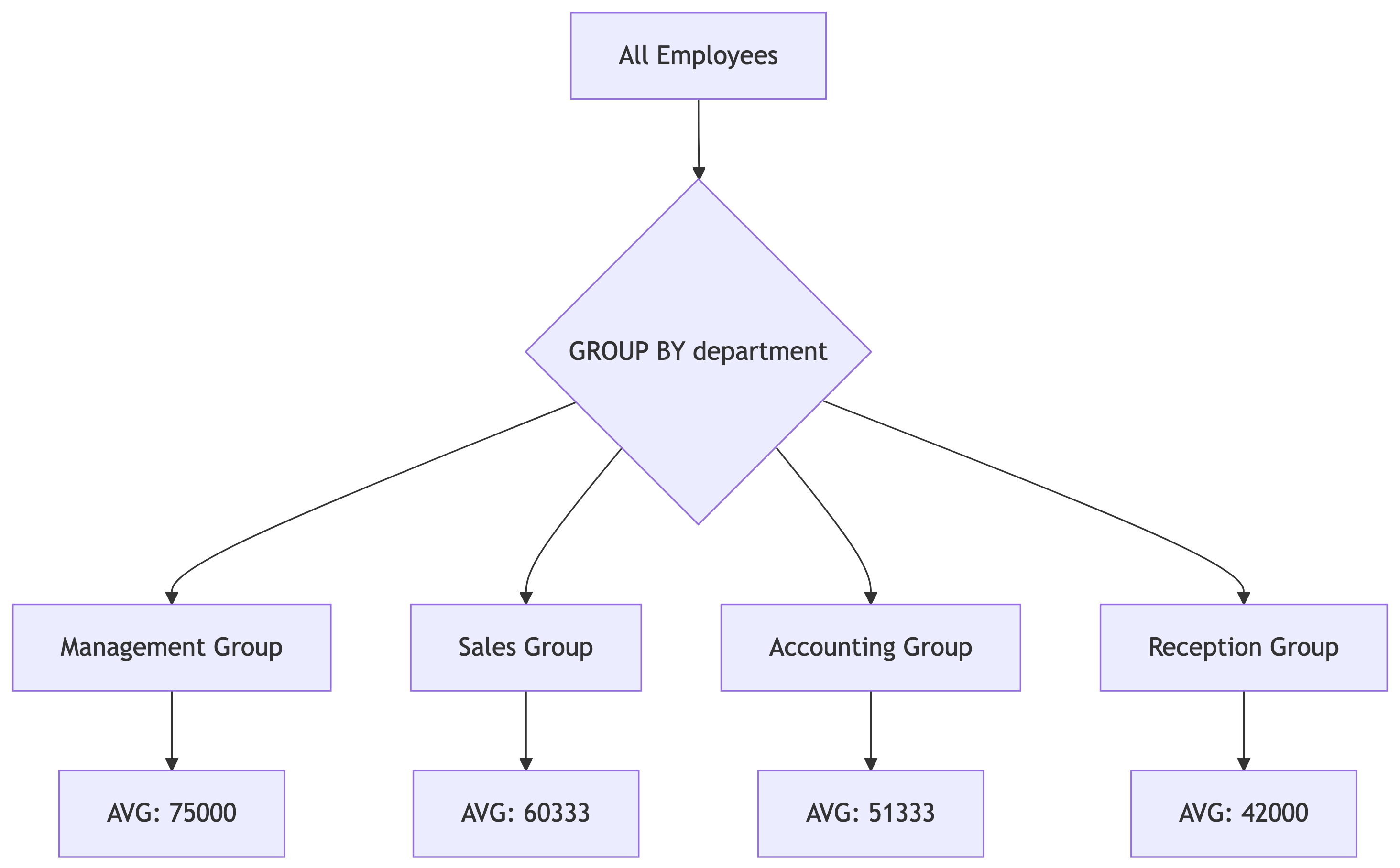
GROUP BY splits data into buckets, then aggregates each bucket separately.
HAVING: Filter After Grouping
Show only departments with more than 1 employee:
| department | num_employees | avg_salary |
|---|---|---|
| Sales | 3 | 60333.33 |
| Accounting | 3 | 51333.33 |
WHERE filters rows BEFORE grouping. HAVING filters AFTER grouping.
Exercise: Department Analysis
Write a query that shows for each department:
- Department name
- Number of employees
- Total salary expense
- Average performance rating (rounded to 1 decimal)
Only include departments where average performance rating > 3.5
Take 4 minutes.
Exercise Solution
| department | num_employees | total_salary | avg_rating |
|---|---|---|---|
| Accounting | 3 | 154000.00 | 3.8 |
| Sales | 3 | 181000.00 | 3.6 |
Management and Reception did not make the cut!
10 Minute Break
When we return: Statistical functions and percentiles!
Up next: Finding the median (and why it matters more than average).
Part 3: Statistics and Percentiles
The Problem with Averages
Pop quiz: A company has 5 employees with these salaries:
$40,000, $42,000, $45,000, $48,000, $500,000
What is the average salary?
Is $135,000 a good representation of “typical” salary? No!
The CEO’s salary skews the average dramatically.
Median: The Middle Value
The median is the middle value when data is sorted.
$40,000, $42,000, $45,000, $48,000, $500,000
The median is $45,000, which better represents “typical.”
Tip
When to use which:
- Mean (average): Data is normally distributed, no outliers
- Median: Data is skewed or has outliers
Finding Median with percentile_cont()
PostgreSQL does not have a built-in MEDIAN() function, but we can use:
| median_salary |
|---|
| 55000 |
The 0.5 means “50th percentile” which is the median.
The WITHIN GROUP Syntax
Let’s break this down:
| Part | Meaning |
|---|---|
percentile_cont(0.5) |
Find the 50th percentile (median) |
WITHIN GROUP |
Required syntax for ordered-set aggregates |
ORDER BY salary_usd |
Which column to calculate percentile on |
Hands-On: Median vs Average
Compare median and average for our employee salaries:
| mean_salary | median_salary |
|---|---|
| 56500.00 | 55000 |
Pretty close! Our data does not have extreme outliers.
What is a Percentile?
A percentile tells you what percentage of values fall below a point.
- 25th percentile: 25% of values are below this
- 50th percentile: 50% are below (the median)
- 75th percentile: 75% are below this
- 90th percentile: 90% are below this
If you score in the 90th percentile on a test, you beat 90% of test-takers.
Calculating Quartiles
Quartiles divide data into four equal parts:
| q1 | q2_median | q3 |
|---|---|---|
| 49000 | 55000 | 61250 |
Using Arrays for Multiple Percentiles
Instead of separate function calls, use an array:
| quartiles |
|---|
| {49000,55000,61250} |
The result is an array. Curly braces indicate array values.
percentile_cont vs percentile_disc
Two versions exist:
| Function | Behavior | Best For |
|---|---|---|
percentile_cont |
Interpolates between values | Continuous data |
percentile_disc |
Returns actual value from data | Discrete data |
Tip
For salaries, percentile_cont is usually more appropriate.
Exercise: Salary Percentile Analysis
Write a query that shows:
- The 10th percentile salary (low end)
- The median salary
- The 90th percentile salary (high end)
Use a single percentile_cont call with an array.
Take 2 minutes.
Exercise Solution
| salary_percentiles |
|---|
| {43400,55000,69550} |
Interpretation:
- 10% of employees make less than $43,400
- 50% make less than $55,000 (median)
- 90% make less than $69,550
Date Arithmetic
Working with Dates in PostgreSQL
PostgreSQL makes date math intuitive:
| days_between |
|---|
| 365 |
Subtracting dates gives you the number of days between them.
Hands-On: Calculate Tenure
How long has each employee been with the company?
| full_name | hire_date | today | days_employed |
|---|---|---|---|
| Stanley Hudson | 2004-11-20 | 2026-01-19 | 7730 |
| Michael Scott | 2005-03-24 | 2026-01-19 | 7606 |
| Jim Halpert | 2005-10-05 | 2026-01-19 | 7411 |
EXTRACT(): Pull Parts from Dates
EXTRACT(part FROM date) gets specific components:
| full_name | hire_date | hire_year | hire_month | day_of_week |
|---|---|---|---|---|
| Michael Scott | 2005-03-24 | 2005 | 3 | 4 |
DOW = Day of Week (0=Sunday, 1=Monday, etc.)
DATE_PART(): Alternative Syntax
DATE_PART('part', date) does the same thing:
| full_name | hire_year | hire_quarter |
|---|---|---|
| Michael Scott | 2005 | 1 |
| Angela Martin | 2006 | 3 |
Use whichever syntax you prefer. They are equivalent.
Grouping by Date Parts
How many employees were hired each year?
| hire_year | num_hired |
|---|---|
| 2004 | 1 |
| 2005 | 3 |
| 2006 | 2 |
| 2007 | 2 |
Interval Arithmetic
You can add intervals to dates:
| hire_date | one_year_later | ninety_days_later |
|---|---|---|
| 2005-10-05 | 2006-10-05 | 2006-01-03 |
Exercise: Login Analysis
Write a query that shows:
- Employee name
- Their last login date/time
- How many days ago they logged in (from CURRENT_DATE)
Only include employees who HAVE logged in (not NULL).
Order by most recent login first.
Take 3 minutes.
Exercise Solution
| full_name | last_login | days_since_login |
|---|---|---|
| Dwight Schrute | 2026-01-16 08:01:00 | 3 |
| Jim Halpert | 2026-01-16 08:03:00 | 3 |
| Kevin Malone | 2026-01-16 09:30:00 | 3 |
Note: I cast last_login to DATE to get whole days.
Homework 2 Preview
Assignment Overview
Homework 2 covers everything we learned today:
- Q1: CREATE TABLE with correct data types
- Q2: Import data with
\COPY - Q3-Q5: Math operators and aggregates
- Q6-Q7: Percentile functions
- Q8-Q10: Date arithmetic and grouping
You will use the stackoverflow database with three tables:
currency_rates(CSV). Create table and import a CSV.country_stats(SQL to execute)response_timeline(SQL to execute)
Q1 and Q2 Tips: Creating and Importing
You will define a currency_rates table based on sample CSV data.
Sample data you will see:
rate_date,currency_code,currency_name,exchange_rate,is_major_currency
2025-01-01,USD,US Dollar,1.000000,true
2025-01-01,EUR,Euro,0.8523,trueChoose types carefully:
rate_dateneeds a DATE typecurrency_codeis always 3 charactersexchange_rateneeds decimal precision
Q3 and Q4 Tips: Math Functions
Q3 asks for ABS():
Remember that ABS gives the distance from zero:
Q4 asks for ROUND() and percentages:
Watch for integer division! Cast if needed.
Q5 Tips: GROUP BY with HAVING
You will group by currency and filter with HAVING.
Common mistake: Using WHERE instead of HAVING for aggregate conditions.
-- WRONG: WHERE cannot filter on aggregates
SELECT currency_code, COUNT(*)
FROM currency_rates
WHERE COUNT(*) = 12 -- ERROR!
GROUP BY currency_code;
-- RIGHT: Use HAVING for aggregate conditions
SELECT currency_code, COUNT(*)
FROM currency_rates
GROUP BY currency_code
HAVING COUNT(*) = 12; -- Correct!Q6 and Q7 Tips: Percentiles
Q6: Finding the median
Do not forget WITHIN GROUP! It is required.
Q7: Using arrays for quartiles
The ARRAY keyword is essential.
Q8 and Q9 Tips: Date Arithmetic
Q8: Subtracting dates gives days:
Q9: EXTRACT for grouping by time parts:
Remember to GROUP BY the same expression you SELECT.
Q10 Tips: Self-Join
The hardest question! You need to compare January and December rates.
Strategy: Join the table to itself:
Use table aliases (jan, dec) to distinguish the two instances.
Common Mistakes to Avoid
- Forgetting to alias calculated columns
- Integer division giving wrong results
- Using WHERE instead of HAVING with aggregates
Testing Your Queries Locally
Before submitting:
- Run your query in Beekeeper Studio or psql
- Verify the output looks reasonable
- Check that column aliases match what the question asks
- Make sure ORDER BY direction is correct (ASC vs DESC)
Pro tip: Start simple, then add complexity.
Questions?
Topics we covered today:
- Data types (INTEGER, NUMERIC, TEXT, DATE, BOOLEAN)
- Importing data with
\COPY - Math operators (+, -, *, /, %, ABS, ROUND)
- Aggregates (SUM, AVG, COUNT, MIN, MAX)
- Percentiles (percentile_cont with WITHIN GROUP)
- Date arithmetic (subtraction, EXTRACT)
What questions do you have?
Next Week Preview
Chapter 6: Joining Tables
We will learn how to combine data from multiple tables:
This is where SQL gets really powerful!
Thank You!
Reminders:
- Homework 2 due date: Check Canvas
- Office hours: Check Canvas for schedule
- Questions: Post on Discord or email
Good luck with the assignment!